ベクトル検索とは?ハイブリッド検索で活用
ベクトル検索とは、単語や文章の「意味」を数値化(ベクトル化)し、その類似度をもとにデータを検索する手法を指します。従来のキーワード一致による検索とは異なり、表記が違っても「意味的に近い情報」を探し出せるのが大きな特徴です。
AI技術の進化に伴い、その重要性は急速に高まっています。本記事では、以下のポイントを中心にわかりやすく解説します。
- ベクトル検索の基本的な仕組みと特徴
- 文字列検索(キーワード検索)との違い
- ベクトル検索を最大限に活かす「ハイブリッド検索」の活用メリット
- ハイブリッド検索に対応したQuickSolution
- QuickSolutionの生成AI連携(RAG対応)
目次
ベクトル検索の特徴
ベクトル検索(Vector Search)の主な特徴は、検索キーワードと対象の文字列が一致していなくても、意味やニュアンスの近さをもとに情報を探し出せる点にあります。単なる「文字の並び」ではなく、言葉がもつ「意味」をベクトル(数値)として計算することで、人間の感覚に近い検索を実現できます。
従来の文字列検索では、キーワードがドキュメント内に含まれていない場合、検索結果には表示されません。一方でベクトル検索は、以下のように表現が異なる場合でも、意味の類似性を検知してヒットさせることができます。
検索キーワード:「パソコンの動作が重い」の例
- ベクトル検索
- 結果:「PCのパフォーマンスを改善する方法」という記事がヒットする
- 理由:「動作が重い」と「パフォーマンス改善」が、意味的に関連している(近いベクトルにある)と判断できるため
- 従来の文字列検索(キーワード検索)
- 結果:ヒットなし
- 理由:「動作が重い」という具体的な文字列が含まれる文書しか探せないため
このように、言葉の選び方や表現が多様なデータに対して、ベクトル検索は非常に有効です。とくに以下のような情報の検索で強みを発揮します。
- FAQ(よくある質問):ユーザの質問文と回答文の表現が一致しない場合でも対応可能
- 問合せ履歴:口語表現や曖昧な表現の意図を汲み取り対応可能
RAGとの相性もよい
ベクトル検索は単なる検索用途にとどまらず、RAG(Retrieval-Augmented Generation:検索拡張生成)の回答精度を高める技術としても大きな注目を集めています。RAGは、生成AIが学習していない社内データや最新情報などを外部から検索・抽出し、その内容をもとに回答を生成する技術です。
生成AIは嘘の情報を答える(ハルシネーション)リスクがありますが、RAGを使うことで、根拠に基づいた正確な回答が可能になります。RAGにおいて、生成AIが的確な回答をするためには、その判断材料となる参照情報の質が極めて重要です。ここでベクトル検索が強みを発揮します。
- 質問意図の理解:ユーザの質問が曖昧でも、ベクトル検索なら「意図」を汲み取り、関連性の高いドキュメントを抽出できます。
- 回答品質の向上:従来の文字列検索(キーワード検索)では、単語と一致する情報ばかりを抽出して、AIが偏った回答を生成することがありました。ベクトル検索により、AIに渡す情報の精度が上がり、結果として最終的な回答品質が向上します。
ベクトル検索の仕組み
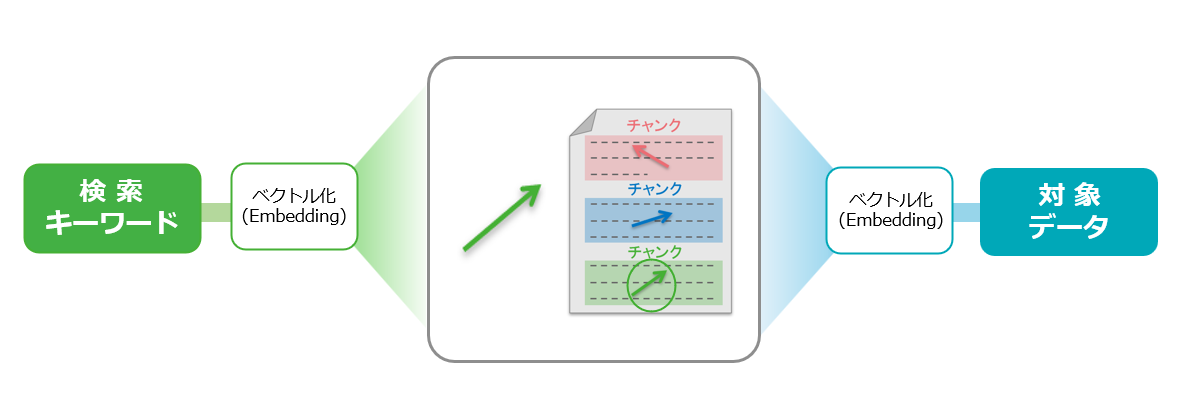
この章ではベクトル検索の流れについて、以下の2つのステップに分けて簡単に説明します。
- データのベクトル化、エンベディング(Embedding)
- ベクトルの比較
1.データのベクトル化、エンベディング(Embedding)
検索対象となるドキュメントやデータを用意し、AIが理解できる数値形式に変換するプロセスをエンベディング(Embedding、埋め込み)と呼びます。このプロセスを経ることで、単語・文章がもつ意味や文脈が反映された、多次元空間上の「座標」をもつ数値の並び(ベクトル)として表現されます。
ベクトル検索を可能にするためのデータ準備は、以下の手順で行われます。
(1)チャンク化
長いドキュメントを意味が途切れない適切な単位(チャンク)に分割します。一度にベクトル化できる情報量には限界があるため、検索時の粒度を細かくするために重要です。
(2)エンベディングの実行
チャンク化された各テキストをエンベディングモデルに入力し、数値の羅列(ベクトル)に変換します。このプロセスで変換したベクトル表現を埋め込み表現(Embedding)と呼びます。
(3)ベクトルDBでの管理
生成された数値ベクトルは、高速な検索のために特化されたベクトルDBに保存・管理されます。
具体的なベクトル化の例
| テキスト | 表現される意味 | ベクトル(イメージ) |
|---|---|---|
| 犬 | ペット、動物、忠実 | v1 = (0.5,0.2,0.6・・・) |
| 猫 | ペット、動物、気まぐれ | v2 = (0.5,0.3,-0.5・・・) |
| 自動車 | 乗り物、機械、速い | v3 = (-0.9,0.7,0.2・・・) |
上記の例では、「犬」と「猫」は「ペット」という共通の意味をもつため、数値ベクトルも近い値(空間上で近い座標)になります。一方、自動車は意味が大きく異なるため、ベクトルは離れた値になります。
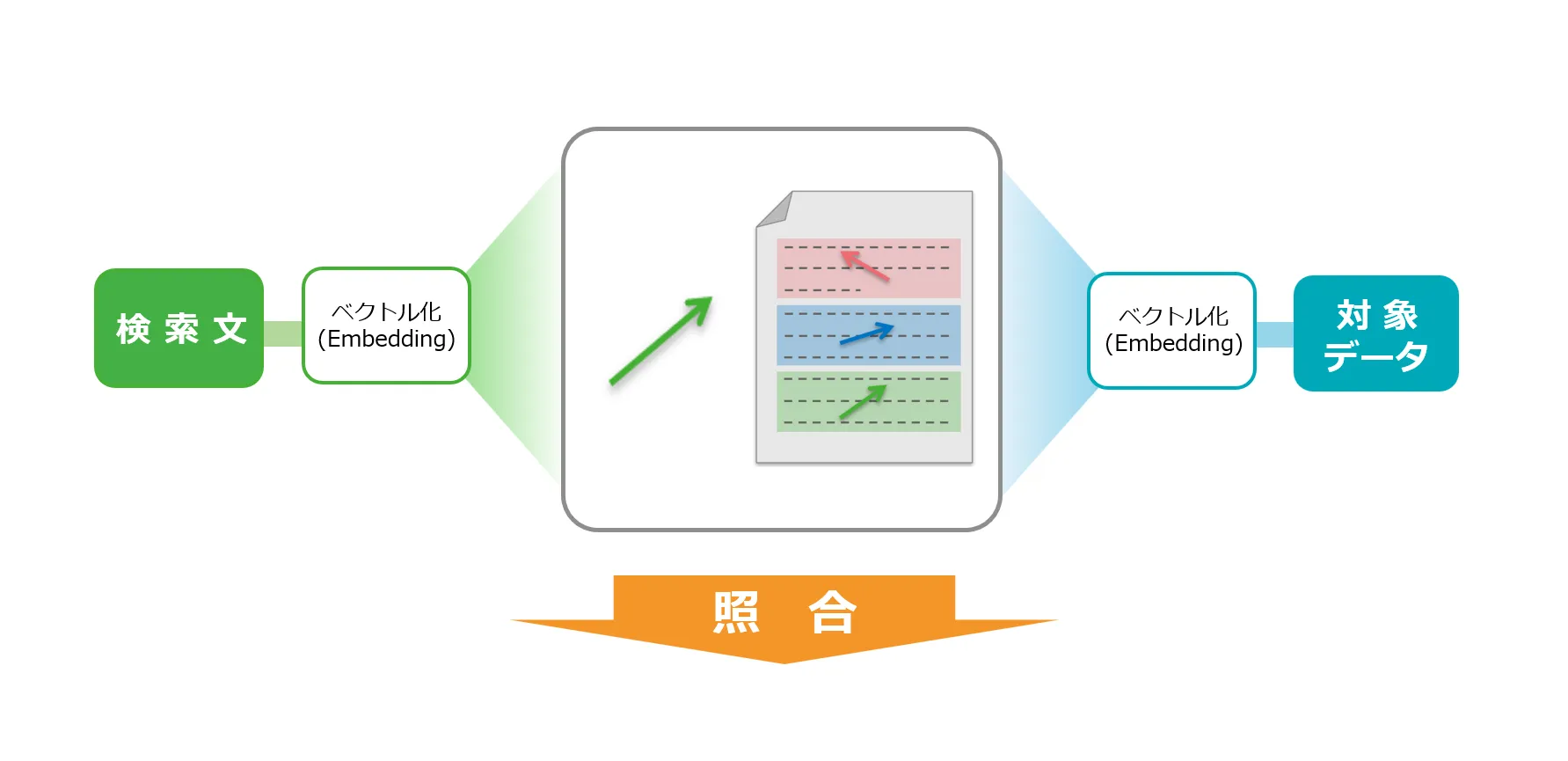
2.ベクトルの比較
データがベクトル化され、ベクトルDBに格納された後、ユーザが検索を行う際の仕組みは以下の通りです。
(1)検索キーワードのベクトル化
ユーザが入力した検索キーワードや文章(例:「愛らしい動物」)も、1.と同様にエンベディングモデルによって数値ベクトルに変換されます。
(2)ベクトルDB内での比較
変換された検索ベクトルと、ベクトルDB内に保存されているすべてのデータベクトルとの間で「類似度」を計算します。この類似度が高いほど、検索意図に近い情報と判断されます。
(3)類似度の高い結果を抽出
計算された類似度が高いデータが検索結果として返されます。
たとえば、ユーザが「家庭で飼える、人懐っこい生き物」という文脈で検索を行った場合、この検索キーワードは多次元空間上で「犬」や「猫」のベクトルの近くに位置づけられます。ベクトルDBは、距離が最も近い「犬」や「猫」に関する情報(v1,v2)を類似度が高いとして優先的にヒットさせます。
結果として、検索キーワードと完全に一致する文字列を含まない「子犬の飼い方」や「猫の品種図鑑」といった、関連性のある情報を柔軟に検索できるのです。この「空間上の距離が意味の近さ」として機能する仕組みこそが、ベクトル検索の柔軟性と精度の源泉となっています。
ベクトル検索と文字列検索(キーワード検索)の違い
ベクトル検索と文字列検索(キーワード検索)は、どちらも情報を探す技術ですが、その仕組みと得意な領域は大きく異なります。結論として、柔軟性を求める場合はベクトル検索、厳密性を求める場合は文字列検索が適しています。
| ベクトル検索 | 文字列検索(キーワード検索) | |
|---|---|---|
| 検索結果 | 意味や文脈が近い結果(表記揺れにも対応) | 特定の単語と一致する結果 |
| 得意な用途 | ユーザの検索意図を汲み取る、柔軟な情報検索(例:FAQ、レビュー) | 探す対象が明確な厳密な検索(例:製品型番、サービス名) |
| 準備 | 検索対象のテキストをチャンクに分割。チャンク単位でエンベディングしてベクトルDBを用意する | 検索対象のテキストを分解してインデックス(索引)を用意する |
| 管理面 | 最新情報に対応するため、ベクトルDBの定期的な更新が必要 | 最新情報に対応するため、インデックスの定期的な更新が必要 |
ベクトル検索は、言葉の意味やニュアンスを理解して検索するため、ユーザが求めている潜在的な意図を汲み取った結果が得られます。「あの映画で出てきたロボットの名前」や「パソコンが動かなくなった時の対処法」など、表現が多様で柔軟な検索結果が求められる場合に有効です。
文字列検索は、特定の単語との一致に特化しています。「最新PC ABC/12345」の仕様や「契約番号 XYZ-12345」の確認など、探す対象が明確で厳密性が求められる場合に最適です。
ベクトル検索を最大限に活かすためのハイブリッド検索
ベクトル検索の精度を高めつつ、弱点も克服するための最善策がハイブリッド検索の活用です。ハイブリッド検索とは、複数の異なる検索手法を組み合わせる技術であり、柔軟性に富むベクトル検索と厳密性に優れた文字列検索(キーワード検索)を組み合わせたシステムを指します。
ベクトル検索は「意味」を捉えるのが得意ですが、「製品型番」や「固有名詞」といった特定のキーワードを正確に探すのは苦手な場合があります。逆に、文字列検索は「厳密な一致」は得意ですが、「意味の類推」ができません。
ハイブリッド検索は、それぞれの弱点を補いながら強みを最大限に活かすことが可能です。
- ベクトル検索の柔軟性:ユーザの意図を汲み取った幅広い検索結果を提供
- 文字列検索(キーワード検索)の厳密性:固有名詞や最新の製品名など、文字列一致が必須な情報を確実にキャッチ
また、RAGの精度向上においてもハイブリッド検索は最適です。RAGの回答品質は生成AIが参照する情報の正確性に依存します。意味を捉えるベクトル検索に加え、文字列検索が「製品型番」や「固有名詞」をピンポイントで特定することで、AIが誤ったドキュメントを引用するリスクを最小限に抑えられます。必要な情報を漏れなく、かつ正確にAIへ提供できるようになるため、この組み合わせにより、検索の網羅性と正確性を両立させ、ユーザ体験とRAGの精度を飛躍的に向上させることができます。
QuickSolutionで社内情報をハイブリッド検索
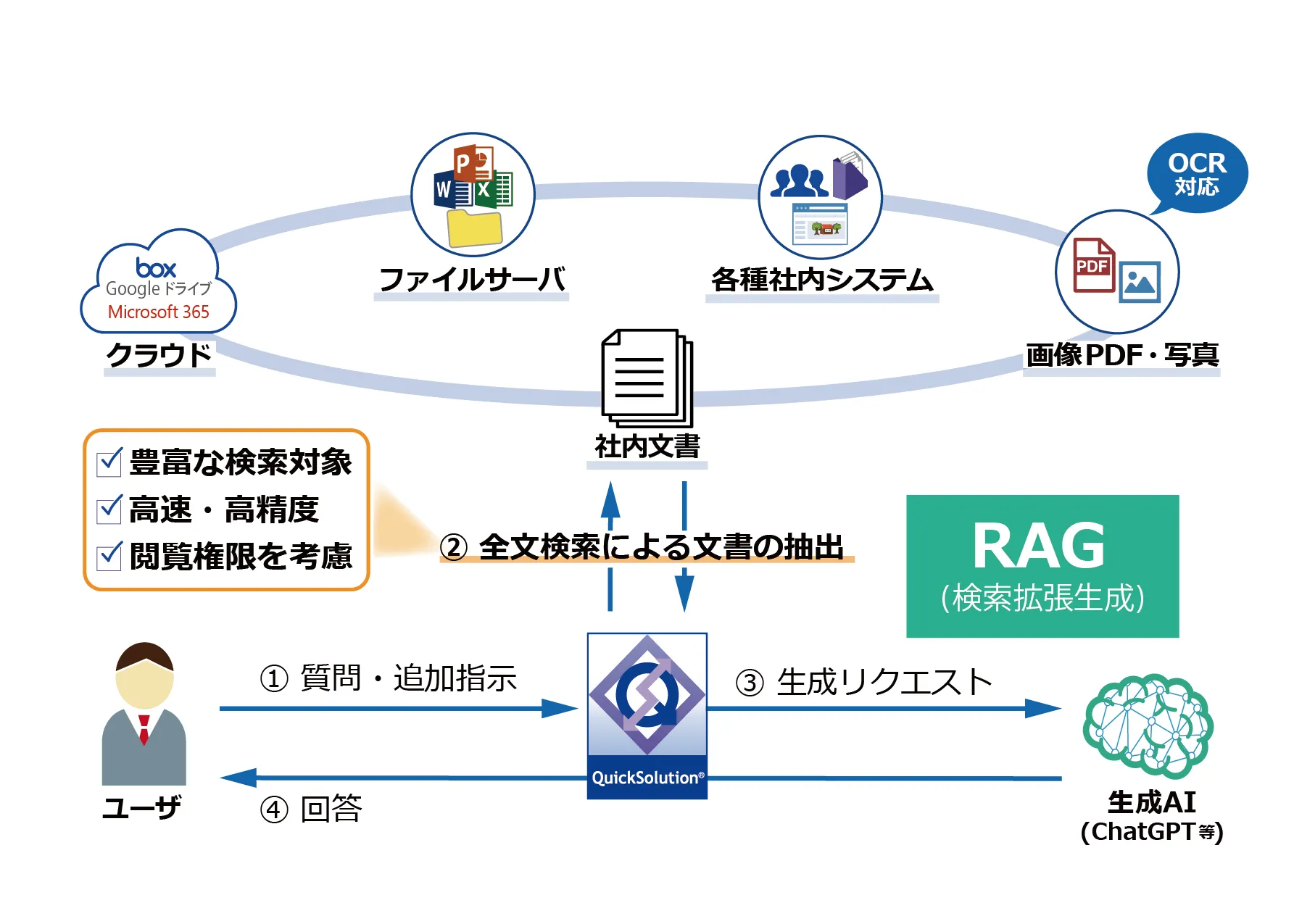
ここからは社内情報をハイブリッド検索で活用できるエンタープライズサーチQuickSolutionを紹介します。
QuickSolutionは、数100TB規模の社内情報でも万全のセキュリティで高速・高精度に横断検索できるシェアNo.1のエンタープライズサーチです。ファイルサーバや各種社内システム、クラウドサービスなどに散在する情報を、横断的に文書の中身まで検索できます。さらに、スキャンした画像PDFなども画像OCR検索で簡単に探し出せます。また、RAGを活用し生成AIと連携することで、社内情報からユーザが知りたい情報を回答する質問応答機能を提供。自律型検索エージェントも搭載しています。
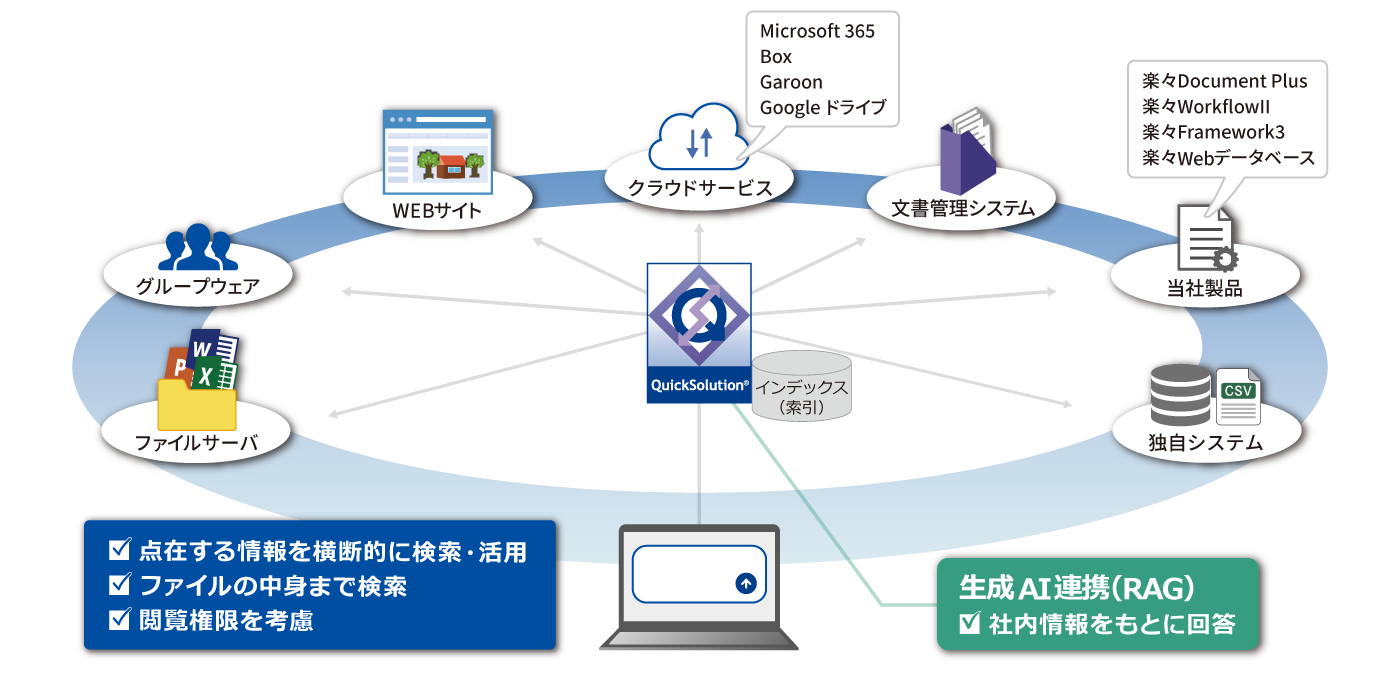
ハイブリッド検索をはじめとした高度な検索機能で、業務効率化/ナレッジ活用/DXを強力に支援します。QuickSolutionのハイブリッド検索の特長を紹介します。
1.漏れや重複のない高精度検索
QuickSolutionは高精度文字列検索と、意味的に近い情報を探し出せるベクトル検索の技術を組み合わせ、綿密なチューニングを重ねることで、ハイブリッド検索を実現しています。
QuickSolutionの文字列検索は社内情報に特化した精度改善により「製品名」「型番」「企業独自のプロジェクト名や略語」などを漏れなく検索できます。ハイブリッド検索では、ベクトル検索で情報を広く拾いながら、文字列検索の精度で絞り込むことで検索結果の品質を高め、情報検索の精度と効率を向上させています。
また、QuickSolutionのハイブリッド検索は「全文スコア」「データ更新日時」「アクセス数」などの考慮や類似文書集約により、高精度で重複のない検索が可能です。高精度かつユーザの意図に沿った結果を提供するハイブリッド検索で社内情報の価値を最大限に引き出し、情報検索にかかる時間の削減も可能です。
2.管理が簡単(ベクトルDB、インデックス)
ベクトル検索を利用する場合には、検索対象のテキストを分割、エンベディングしてベクトルDBを用意する必要があります。また、文字列検索を利用する場合は、検索対象のテキストを分解してインデックス(索引)を用意する必要があります。ベクトルDBやインデックスは、最新情報を検索するために定期更新が必要です。
QuickSolutionはベクトルDBやインデックスの定期更新を自動で行います。検索システムに必要な運用の手間を最小限に抑えているため、管理コストを心配せず導入していただけます。また、社内情報をそのまま検索対象にするため、現状の運用方法を変更不要で導入も簡単です。
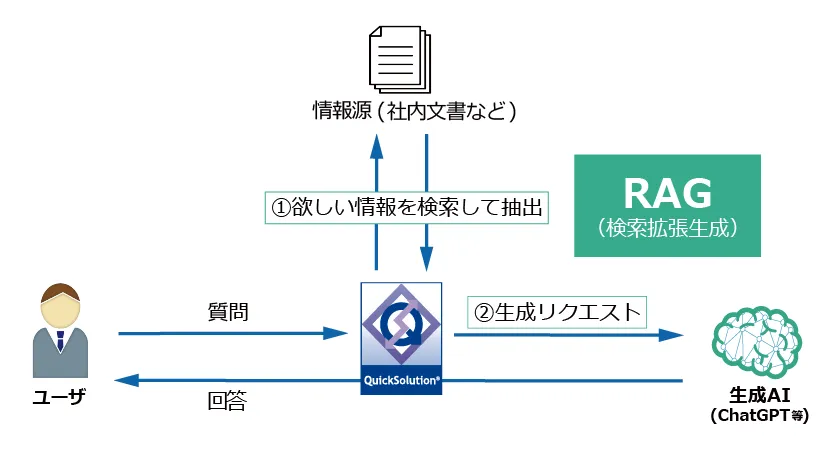
QuickSolutionの生成AI連携
QuickSolutionは、RAGを活用し生成AIと連携することで、社内外に散在する膨大な社内情報からユーザが知りたい情報を回答する質問応答機能を提供。さらに、自律的に検索・評価を繰り返して回答を生成する検索エージェントも搭載しています。
生成AIを活用して的確な回答を得るには、適切な情報を参照させることが重要です。上述のハイブリッド検索によって、ユーザの意図に沿う情報を漏れや重複なく抽出できるため、対話形式で的確な情報を提供できます。
QuickSolutionの生成AI連携(RAG)には、以下の特長があります。詳細は生成AI連携(RAG対応)をご覧ください。
- 社内の豊富な検索対象をそのまま情報源にするため、現状の運用方法を変更不要
- 回答に必要な文書を的確に抽出し正確に回答
- 利用者の閲覧権限を考慮して回答
- 企業内情報を生成AIに学習させず、個人情報/機密情報の流出も防止
まとめ
本記事では、単語の意味や文脈を数値化し類似度で検索するベクトル検索について解説しました。従来の文字列一致に依存する検索とは異なり、ユーザの検索意図を汲み取った柔軟な結果を返せる点が大きな特徴です。
とくに、以下の点でベクトル検索の重要性は高まっています。
- 柔軟な情報検索:表現が多様なFAQやマニュアル検索などで高い効果を発揮
- RAGの精度向上:生成AIに渡す参照情報の質を高め、回答の正確性を担保
しかし、ベクトル検索には固有名詞の検索が苦手という弱点があります。この弱点を克服し、それぞれの強みを最大限に活かすのが、ベクトル検索と文字列検索を組み合わせた「ハイブリッド検索」です。
AI時代において、網羅性と正確性を両立させるハイブリッド検索の社内導入は、ビジネスにおけるデータ活用を最適化する鍵となるでしょう。
エンタープライズサーチQuickSolutionは社内情報のハイブリッド検索に対応しています。さらにRAGを活用し生成AIと連携することで、社内情報からユーザが知りたい情報を回答する質問応答機能も提供しています。膨大な社内情報の潜在的な価値を最大限に引き出し、業務効率化/ナレッジ活用/DXを強力に支援します。