AI(人工知能)
AI(人工知能)とは?
Wikipediaによると、AI(Artificial Intelligence、人工知能)とは、人間の知的能力をコンピュータ上で実現する、様々な技術・ソフトウェア・コンピュータシステムを指します。応用例としては、自然言語処理(機械翻訳・かな漢字変換・構文解析・形態素解析等)、専門家の推論・判断を模倣するエキスパートシステム、画像データを解析し特定のパターンを検出・抽出する画像認識等があります。
引用:「人工知能」『フリー百科事典 ウィキペディア日本語版』。2023年4月5日(水) 05:03 UTC、URL: https://ja.wikipedia.org
AIの歴史
AIの歴史の中で自然言語処理、音声認識、統計的自然言語処理などが主な技術であることが分かります。2010年代に入ると、表現学習により機械が自動で特徴設計をするディープラーニング(深層学習)が提唱され、第三次人工知能ブームが始まりました。
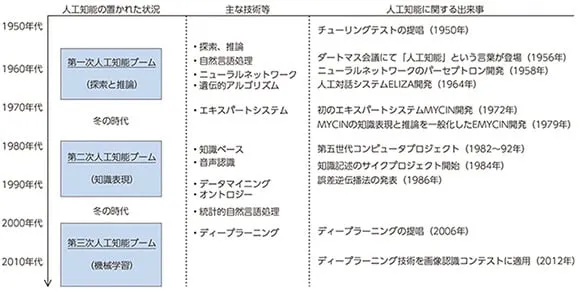
その後、2010年代の終わりから2020年代にかけて、自然言語処理の分野で「BERT」やGPTシリーズ(GPT-2/GPT-3/GPT-4)などの汎用的な大規模言語モデルが次々と開発され、大きな技術革新が進んでいます(下記)。また、2022年末からは、これらの大規模言語モデルをベースとして開発されたChatGPTなどの対話型AIが次々と発表され、専門媒体にとどまらず、ニュース番組でも取り上げられるなど大きな関心を集めています。
- Google社が言語モデル「BERT」を発表(2018年)
- OpenAI社が言語モデル「GPT-2/GPT-3」を発表(2019年/2020年)
- OpenAI社がGPT-3.5をベースとする対話型AI「ChatGPT」を発表(2022年)
- Google社が対話型AI「bard」を発表(2023年)
- OpenAI社が言語モデル「GPT-4」を発表(2023年)
2022年~は、画像、文章、音声・音楽などさまざまなコンテンツを生成する「生成AI(ジェネレーティブAI)」にも大きな進展がありました。自然言語処理の分野で前述のChatGPTが登場した他、画像処理の分野では「DALL·E 2」や「Stable Diffusion」が登場し、人が生成したものと遜色ない精度に注目が集まっています。
AIの分類
AIには様々な種類があり、下記の図のように分類することができます。
まず、AIは大きくルールベースと機械学習に分けられると考えています。
ルールベースでは人がルールを設定します。「If~then~else」のようにルールを人が書いていきます。機械学習では「大量データから統計解析によりルールを自動生成」することがポイントです。
機械学習は狭義の機械学習と深層学習に分けられます。狭義の機械学習は「人が特徴設計」する必要があります。一方、深層学習は表現学習により自動で特徴設計します。
AIの処理手順を大きく特徴設計とルール生成に分けて考えると、ルールベースはどちらも人が行う、狭義の機械学習は、特徴は人、ルールは自動、深層学習はどちらも自動となります。これだけ見ると、全て「深層学習」でよいのではと思いますが、機械学習は大量データが必要ということと、深層学習はさらにハイパーパラメータ問題というものを解決する必要があります。
これらの理由により、弊社では狭義の機械学習をベースに、ルールベースで実用化レベルに上げるという方針、深層学習は画像認識等、必要なシーンで活用する方針で進めています。
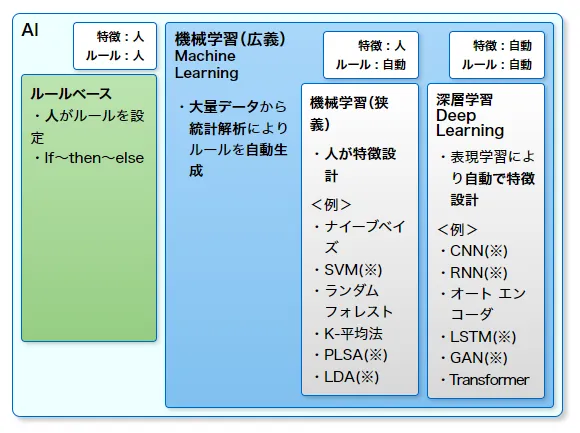
SVM:Support Vector Machine(サポートベクターマシン)、分類器、教師あり学習
PLSA:Probabilistic Latent Semantic Analysis、確率的潜在意味解析法、クラスタリング、教師なし学習
LDA:Latent Dirichlet Allocation、トピック抽出、クラスタリング、教師なし学習
CNN:Convolutional Neural Network(畳み込みニューラルネットワーク)、画像処理用
RNN:Recurrent Neural Network(再帰型ニューラルネットワーク)、音声/自然言語処理用
LSTM:long short-term memory(長・短期記憶)、自然言語処理用
GAN:Generative adversarial networks(敵対的生成ネットワーク)、画像生成用
機械学習の分類
AIの中でも、機械(コンピュータ)が「訓練データ」もしくは「学習データ」と呼ばれるデータを使って学習し、ルールやパターンを自動生成することを「機械学習」と⾔います。機械学習は「教師あり学習」「教師なし学習」「強化学習」の3種類に分類されます。
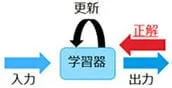
教師あり学習
教師あり学習は、入力に対する出力が正解データに近付くように学習器を更新していく手法です。例えば猫の画像を入力で与えて、出力が犬であれば、正解は猫ですよと教えることにより学習器を更新していきます。
教師あり学習は分類タスクと回帰タスクに分けられます。分類タスクは出力がクラス、すなわちラベル付け(離散値)の問題です。一方の回帰タスクは出力が連続する数値となる問題です。スパムメールの分類、手書き文字認識等は分類タスク、株価の予測や気象分析は回帰タスクです。
教師あり学習は段階や目的によって呼称があり、代表的なものを紹介します。
①事前学習
学習の最初の段階で、大規模なデータを用いて学習器を生成します。この段階では、特定のタスクを目的とせず、言語そのものや特定のパターンを学ぶことを目的とします。
②ファインチューニング/微調整(※)
事前学習で生成した学習器を特定のタスクに適応させる学習です。適応させるタスク向けのデータを用意し、学習器の一部もしくは全体を微調整します。
③転移学習(※)
既に特定のタスク向けに学習された学習器に新たな学習を追加し、別のタスクに転用させる学習です。データをゼロから学習させる必要がないため効率的な学習が期待できます。
④文脈内学習
GPT-3、GPT-4などの生成AIが持つ学習能力で、少量の例を与えるだけでその文脈からパターンを学習し、そのパターンに沿った文章を生成します。この学習では学習器は更新されません。
※既に学習された学習器に対してさらに学習を追加することから、まとめて追加学習と呼ばれることもあります。教師なし学習
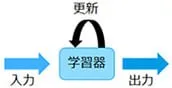
教師なし学習は、正解ラベルの付いていないデータを与えて学習器を更新する⼿法です。簡単な例として、Googleのサジェスト等があります。Googleは全利用者の検索キーワードを蓄積しています。例えば、「京都スペース」と入れると、「観光」「紅葉」等が出てきます。これは「京都」の次のキーワードを人が教えているのではありません。大量の入力キーワードのみで学習器を更新しているのです。AIというと「教師あり学習」をイメージする人も多いと思いますが、「教師なし学習」も機械学習でありAIであることを覚えておいてください。
教師なし学習の利用用途として、クラスタリング(データのグループ分け)、次元削減、アソシエーション分析、特許/アンケートの分析や、データ可視化等があります。QuickSolution(QS)の統計的自然言語処理も教師なし学習がベースです。
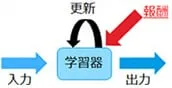
強化学習
強化学習は、試行錯誤を通じて報酬(評価)を与えて学習器を更新する⼿法で、最適化問題等に使われます。この強化学習に深層学習を組み合わせたものが、深層強化学習と呼ばれるもので、AlphaGoはこれによりあれだけ強くなったと言われています。Web広告の選択やマーケティング戦略にも使えるということで弊社でも今後活用を検討していきます。
| 教師あり学習 supervised learning |
教師なし学習 unsupervised learning |
強化学習 reinforcement learning |
|---|---|---|
|
|
|
|
|
|
|
|
|
※参考文献:立命館大学 谷口忠大、11.1.1 機械学習の分類
https://www.slideshare.net/tadahirotaniguchi0624/11-46861748
テキスト情報のグループ分け
テキスト情報をグループ分けする技術には「テキスト分類」と「テキスト・クラスタリング」の2種類があります。「テキスト分類」は教師あり学習、「テキスト・クラスタリング」は教師なし学習です。どちらも重要な技術で、弊社では両方を組み合わせることが必要な場合が多いと考えています。
| テキスト分類 Classification |
テキスト・クラスタリング Clustering |
|
|---|---|---|
| イメージ |
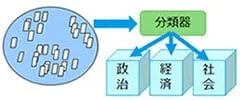
|
|
| 学習 | 教師あり学習 | 教師なし学習 |
| 説明 | 与えられたデータを適切なクラス(入れ物)に振り分ける | 与えられたデータを複数のグループに分ける |
| 主な手法 |
ナイーブベイズ/SVM ランダムフォレスト |
PLSA/LDA K-平均法 |
| 用途 |
スパムメールの分類 Webページを分野別に分類 |
特許/アンケートの分析 トピック推定 |
QuickSolutionとAI
QuickSolutionは、住友電工情報システムが開発したエンタープライズサーチです。
QuickSolutionは、統計的自然言語処理/教師なし機械学習をベースとした機能を備えており、大量の言語データを読み込んで単語の出現傾向を自動的に獲得することにより、大規模なデータの検索も高精度に行います。